Data Backup and Recovery
Loss of Volatile Storage
Volatile storage, such as RAM, stores active logs, disk buffers, and transactions that are currently being executed. If a system crash occurs and volatile storage is lost, it could result in the loss of essential data needed for recovery, making it nearly impossible to restore the system.
Recovery Techniques for Loss of Volatile Storage:
- Checkpointing: Regular checkpoints can be set up to save the contents of the database at multiple stages. This ensures that the system state is saved periodically.
- State Dumping: The active state of the database in volatile memory can be dumped onto stable storage, which should also store logs and transaction details.
- Log Marking: A <dump> marker can be added to the log file whenever the database contents are saved from volatile to stable storage.
Recovery Process:
- After a failure, the system can restore the latest dump.
- Using a redo and undo list based on the checkpoint, the system can recover transactions and restore the database state up to the last checkpoint.
Database Backup & Recovery from Catastrophic Failure
Catastrophic failures occur when stable storage, such as hard drives, gets corrupted, resulting in the loss of all stored data. To address this, two recovery strategies can be employed:
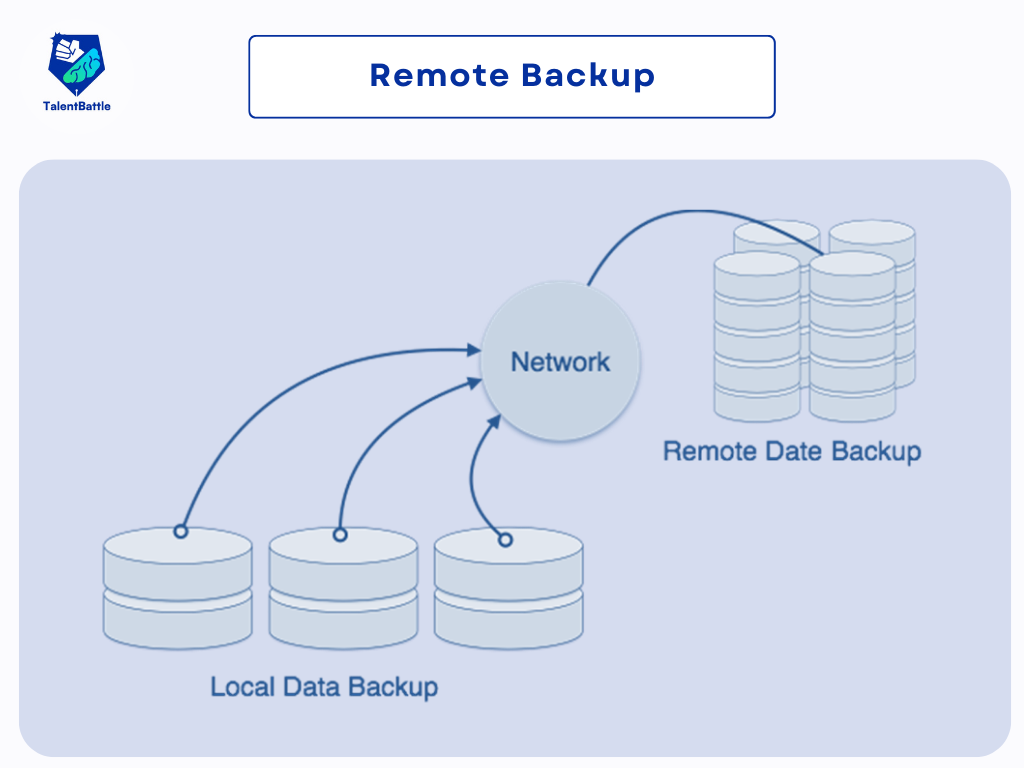
- Remote Backup: A backup copy of the database is stored at a remote location. In case of a catastrophic failure, the remote backup can be restored.
- Log-Based Recovery: Instead of backing up the entire database frequently, backup logs can be taken regularly, and the database itself can be backed up less frequently (e.g., weekly). The logs, which are smaller, can be backed up more often, allowing the database to be restored from the logs.
Remote Backup Options:
- Offline Remote Backup: A backup is manually maintained at a distant location.
- Online Remote Backup: Real-time data is simultaneously backed up at two different locations. In case of a failure, the system can quickly switch to the remote backup, often without users noticing the failure.
Data Recovery
Crash Recovery
A Database Management System (DBMS) handles hundreds of transactions per second, making crash recovery essential. The DBMS uses algorithms to recover lost data after a system crash.
Types of Failures:
-
Transaction Failure: This occurs when a transaction cannot be completed due to logical or system errors.
- Logical Errors: Errors due to issues in the transaction code or internal conditions.
- System Errors: Errors caused by system conditions like deadlock or resource unavailability, which force the DBMS to abort the transaction.
-
System Crash: A crash caused by external factors, such as power failures or operating system errors, that cause the system to abruptly stop.
-
Disk Failure: Physical issues with storage devices, such as bad sectors or a disk head crash, can destroy stored data.
Storage Structure
The storage structure in a DBMS can be categorized into:
- Volatile Storage: Fast, small-capacity storage like RAM and cache memory, which are used for immediate data processing but do not survive system crashes.
- Non-Volatile Storage: Large-capacity storage like hard drives and magnetic tapes, designed to retain data even after system failures.
Recovery and Atomicity
When a DBMS crashes, it must ensure atomicity—either all operations in a transaction are executed or none. Upon recovery, the DBMS checks the state of transactions and ensures they are either completed or rolled back to maintain consistency.
Two techniques help maintain atomicity:
- Logging: Keeping a log of each transaction in stable storage before modifying the database.
- Shadow Paging: Changes are first made in volatile memory, with the actual database updated afterward.
Log-Based Recovery
In log-based recovery, a sequence of logs records each transaction's activities, stored in stable storage for recovery. Logs are written before the database is modified to ensure a reliable recovery.
Process:
- When a transaction starts, the system logs
<Tn, Start>.
- If the transaction modifies data, the system logs
<Tn, X, V1, V2> where X represents the data item, and V1 and V2 represent the old and new values.
- After completion, the system logs
<Tn, Commit>.
Database Modification Approaches:
- Deferred Database Modification: Logs are written to stable storage, and the database is updated only when a transaction commits.
- Immediate Database Modification: The database is modified immediately after every operation.
Example: If a transaction changes a student's city from 'Los Angeles' to 'San Francisco,' the following logs are recorded:
<Tn, Start><Tn, City, 'Los Angeles', 'San Francisco'><Tn, Commit>
Recovery Using Log Records
During recovery:
- If both
<Ti, Start> and <Ti, Commit> are present, the transaction is redone.
- If only
<Ti, Start> is present, but not <Ti, Commit> or <Ti, Abort>, the transaction is undone.
Recovery with Concurrent Transactions
With multiple concurrent transactions, logs may become interleaved, making recovery more complex. To manage this, DBMSs often employ checkpoints, which periodically save the database state and clear previous logs.
Checkpoint Process:
- A checkpoint marks a consistent state in the database where all prior transactions are committed.
- After a crash, the system can roll back or forward from the checkpoint using logs.
Recovery from a Crash:
- The system reads logs backward from the last checkpoint.
- Two lists are maintained:
- Redo-List: Transactions with
<Tn, Start> and <Tn, Commit> are redone.
- Undo-List: Transactions with
<Tn, Start> but without <Tn, Commit> are undone.
Conclusion
A DBMS's data recovery and backup system ensures that the integrity and atomicity of transactions are preserved, even in the face of crashes or catastrophic failures. By employing techniques like logging, checkpointing, and remote backups, a DBMS can recover and maintain the consistency of its database across various failure scenarios.

